Logstash
실습 진행
NLP
현재 제공되는 클라우드를 어떻게 효율적으로 사용할 수 있을까.
ChatGPT
그냥 ChatGPT는 신뢰도를 보장할 수 없음. 서비스 제공자가 직접 신뢰도를 보장해야 함. 답변을 컨트롤할 수 있고, 신뢰도를 보장할 수 있음.
Word Embedding
NLP는 광대해서 전부 다루기는 어려움.
<Word2Vec>
- 사람의 자연어를 기계가 이해할 수 있게.
- 단어를 벡터로 치환함.
- 단어의 유사도를 측정할 수 있게됨.
- Ex) The cat purrs / The cat hunts mice.
- 비슷하거나 같은 관계의 단어는 비슷한 Vector를 가진다.
Elasticsearch NLP
초기( 7.3 ver): Brute force라는 알고리즘 사용 - 무차별 대입 검색
8.x ver ~ HNSW & KNN 멀티레이어
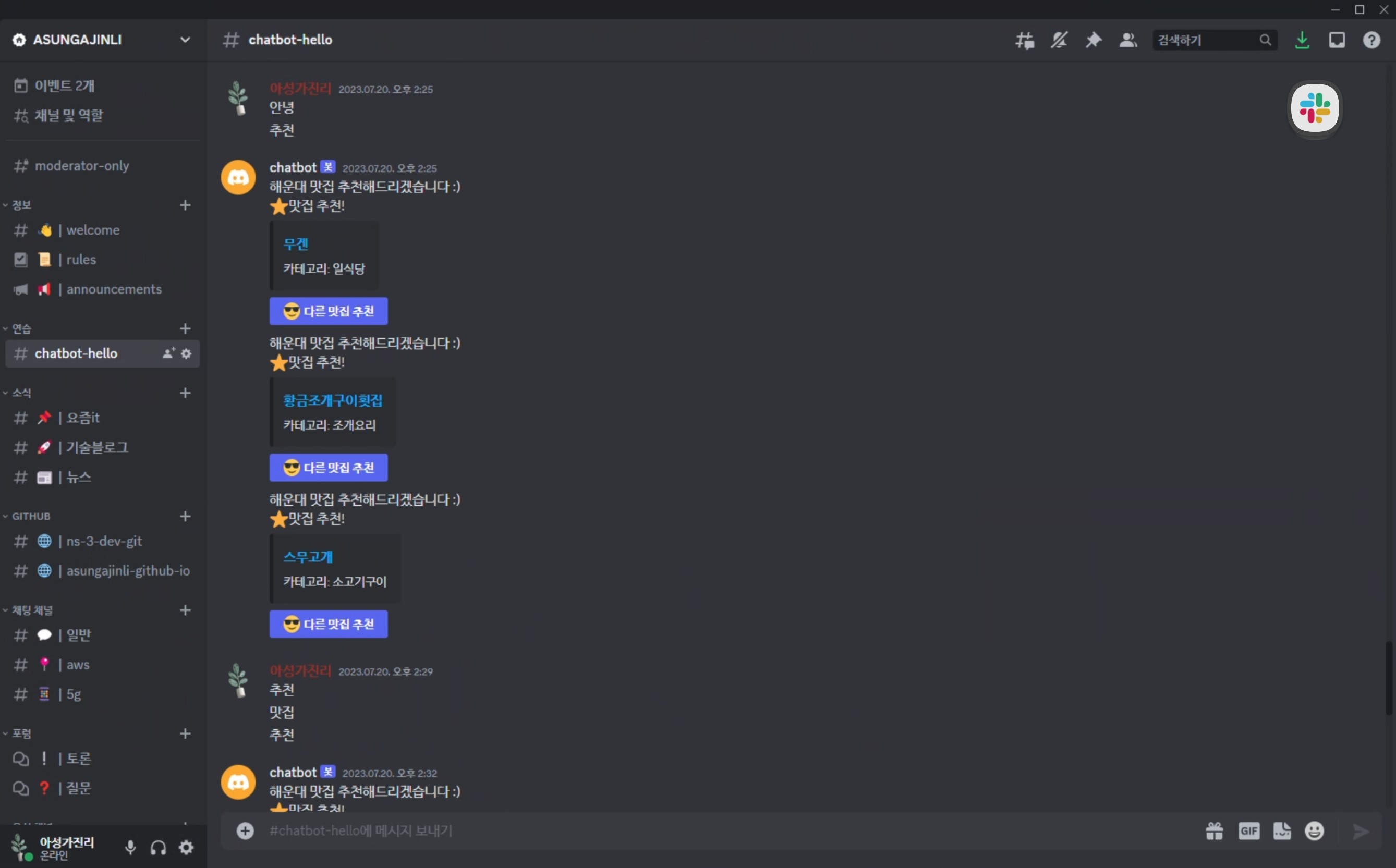
AWS 챗봇
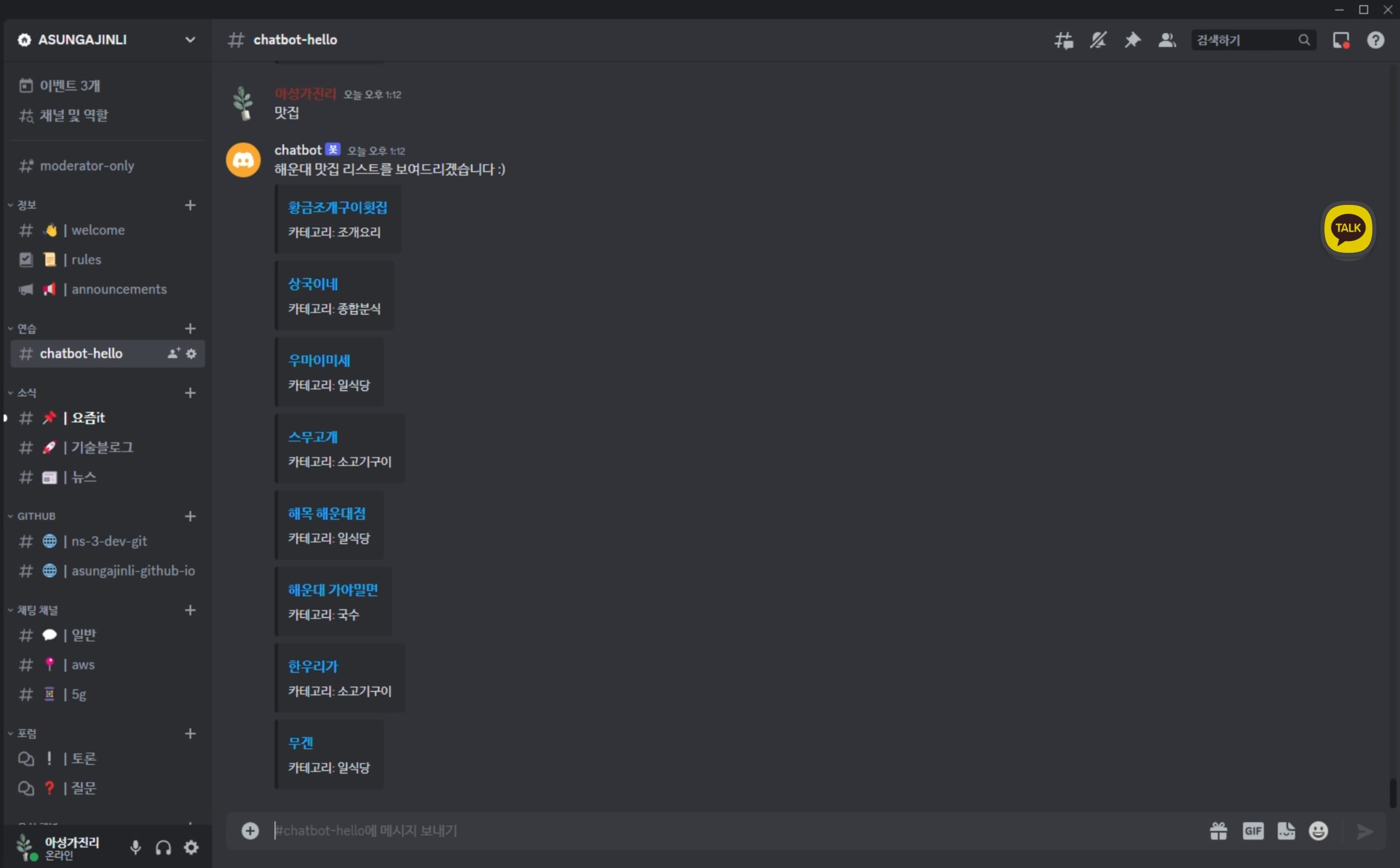
강의에서는 slack으로 챗봇을 만들어 보았지만, 디스코드로 챗봇을 다시 만들어 보려고 한다.
서버 생성
우선 새 서버를 생성한다. 나는 이미 개인적으로 사용하는 서버가 있으므로 그곳에서 진행한다.
서버를 만들었으면, 채널도 하나 생성해준다.
디스코드 앱 세팅
디스코드 앱은 Discord Developer Portal에서 만들 수 있다.
‘New Application’을 클릭하여 앱을 만든다. Name은 아무렇게나 지어도 상관없다. 봇을 서버에 추가 했을 때 봇이 가지는 역할(@role)이 이 app 이름으로 설정된다.
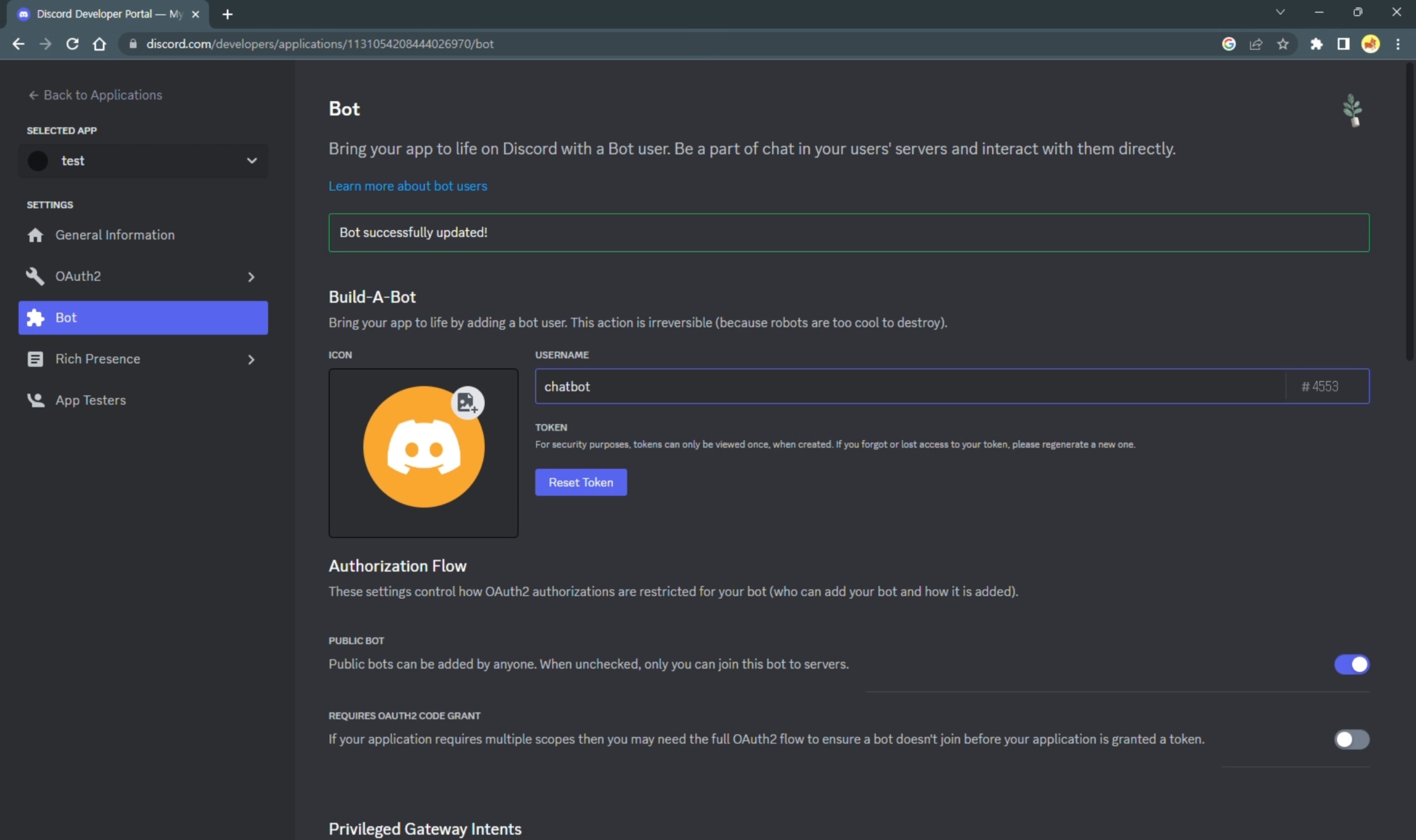
Bot 이름을 설정해준다.
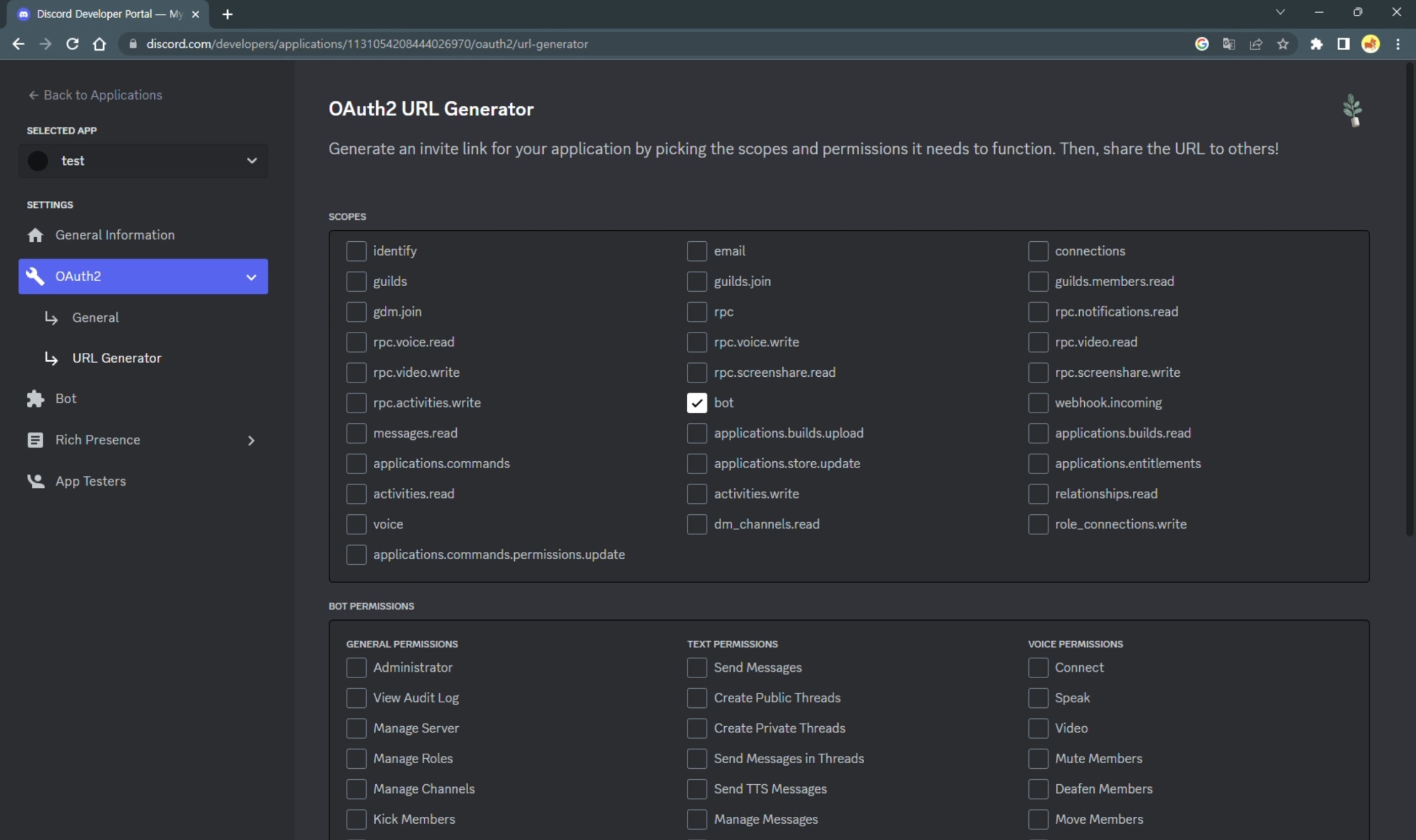
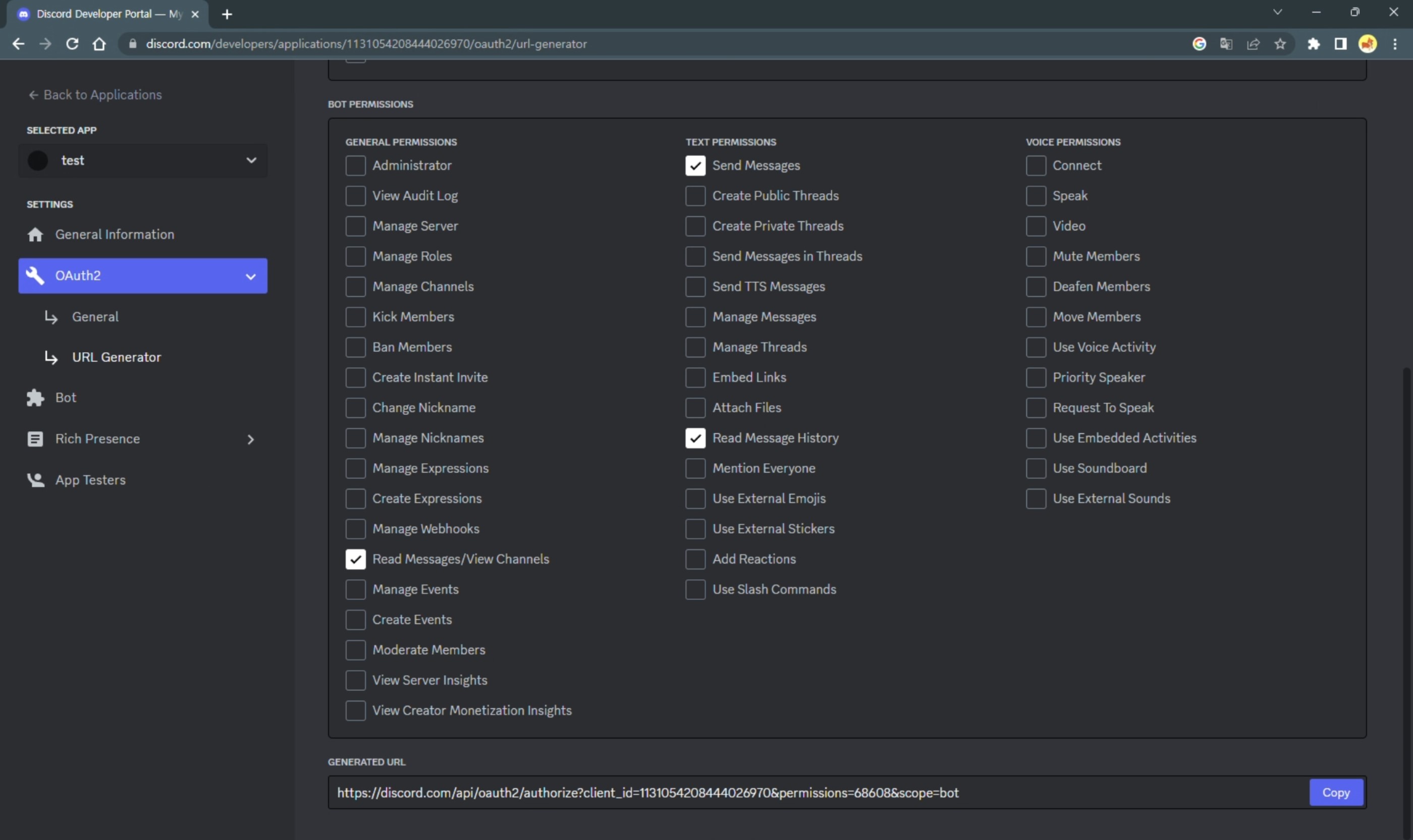
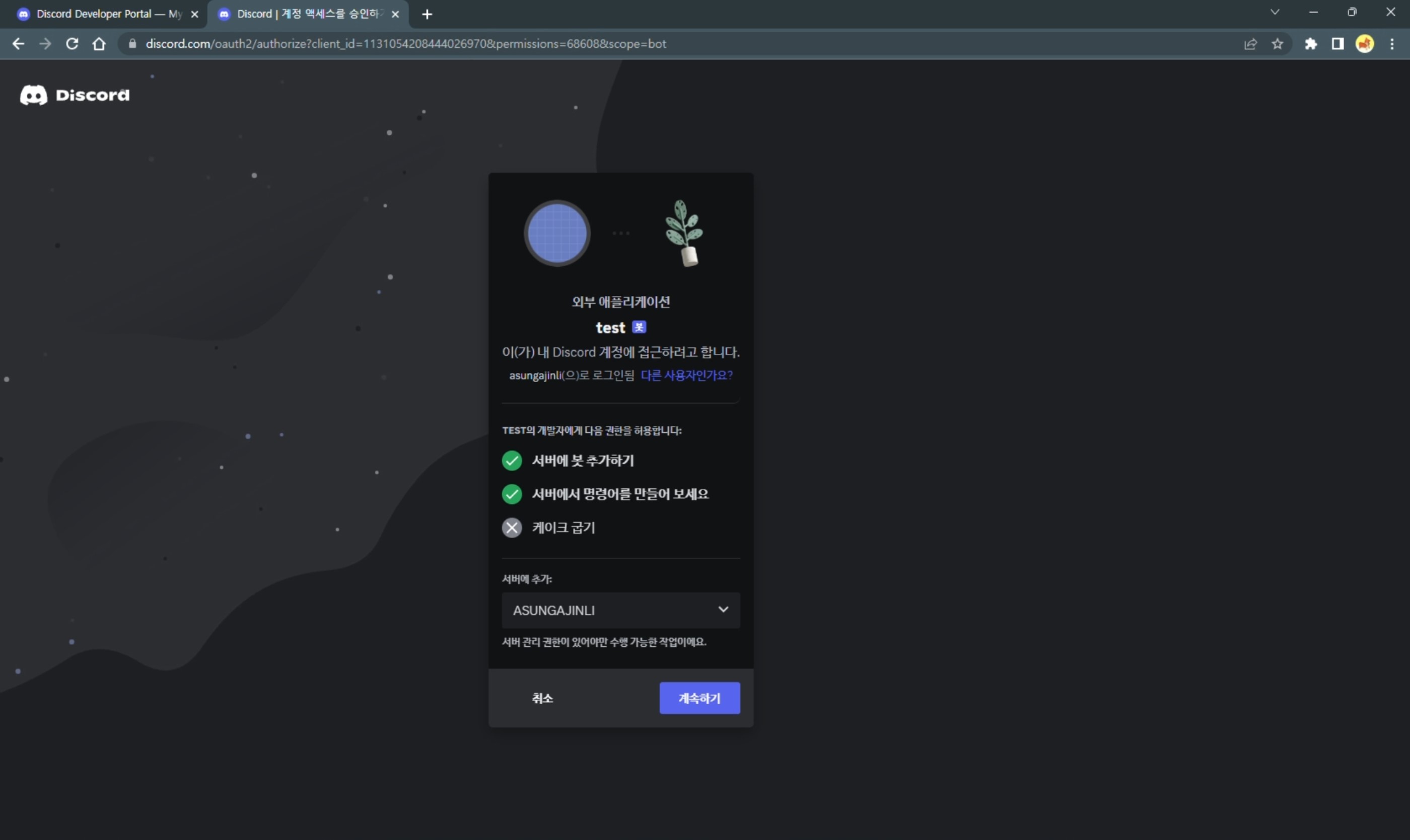
OAuth2의 URL Generator 메뉴에서 권한 설정을 해주고 URL을 설정한다. 해당 URL로 접속하면 봇을 디스코드 서버로 초대할 수 있고, 초대된 봇을 확인할 수 있다.
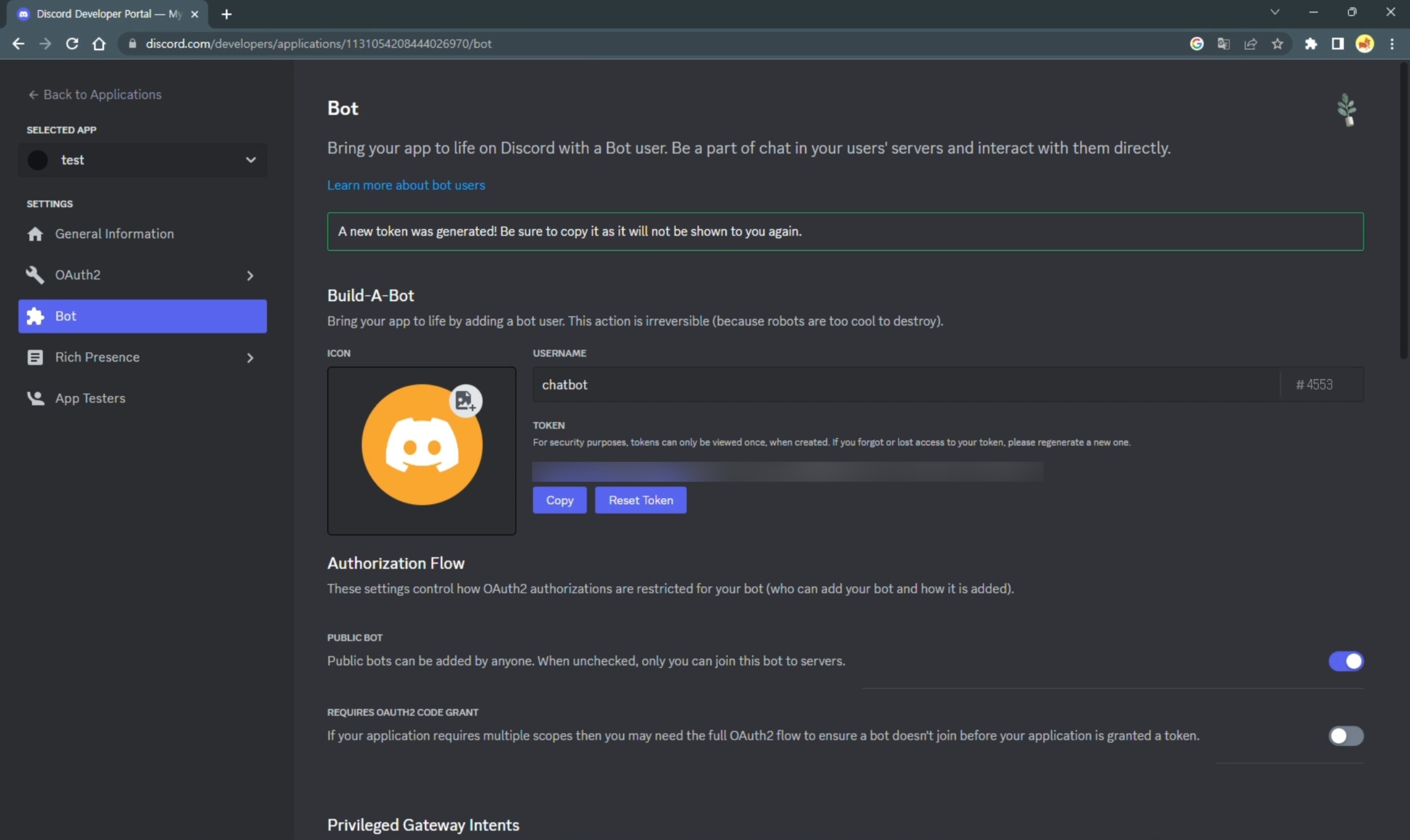
아래 ‘Reset Token’ 버튼을 눌러 토큰을 생성 한 후 복사해서 잠시 저장해 둔다.
봇 개발하기
봇을 만들 때 AWS의 Cloud9 서비스를 이용해 보려고 한다.
먼저 환경을 생성한다.
vscode 환경과 흡사해 크게 어렵지 않을 것이다.
discord.py 2.0버전을 활용하기 위해서는 python 3.8 이상 버전이 필요하다. 원래는 아마 3.7 버전이 설치되어 있을 것이다. 아래 방법이 안되면 인터넷 뒤져보자.
sudo amazon-linux-extras enable python3.8
sudo yum install python3.8
sudo ln -sf /usr/bin/python3.8 /usr/bin/python3
sudo yum remove python3.7
discord.py를 설치한다.
pip install discord.py
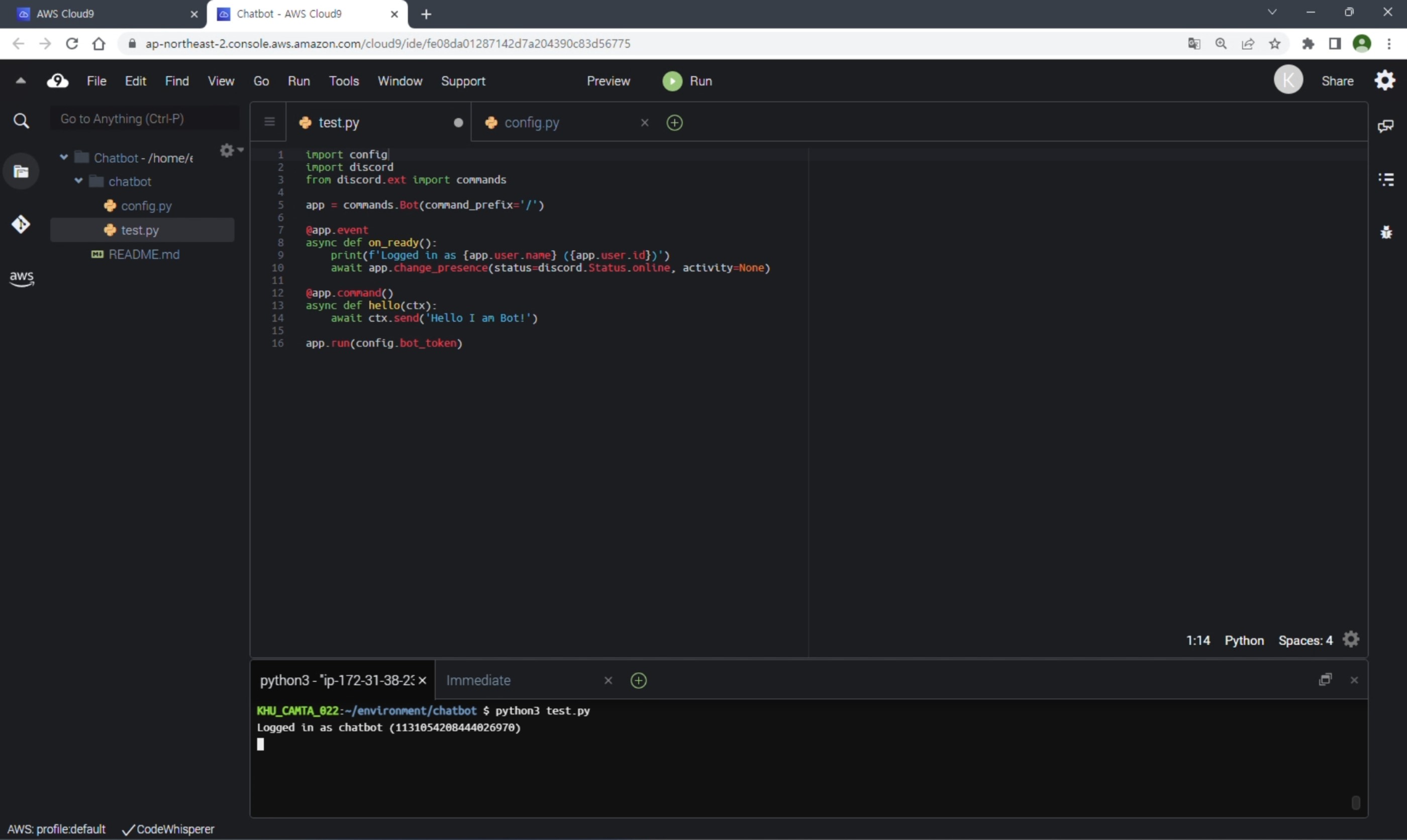
test.py
import config
import discord
from discord.ext import commands
app = commands.Bot(command_prefix='/')
@app.event
async def on_ready():
print(f'Logged in as {app.user.name} ({app.user.id})')
await app.change_presence(status=discord.Status.online, activity=None)
@app.command()
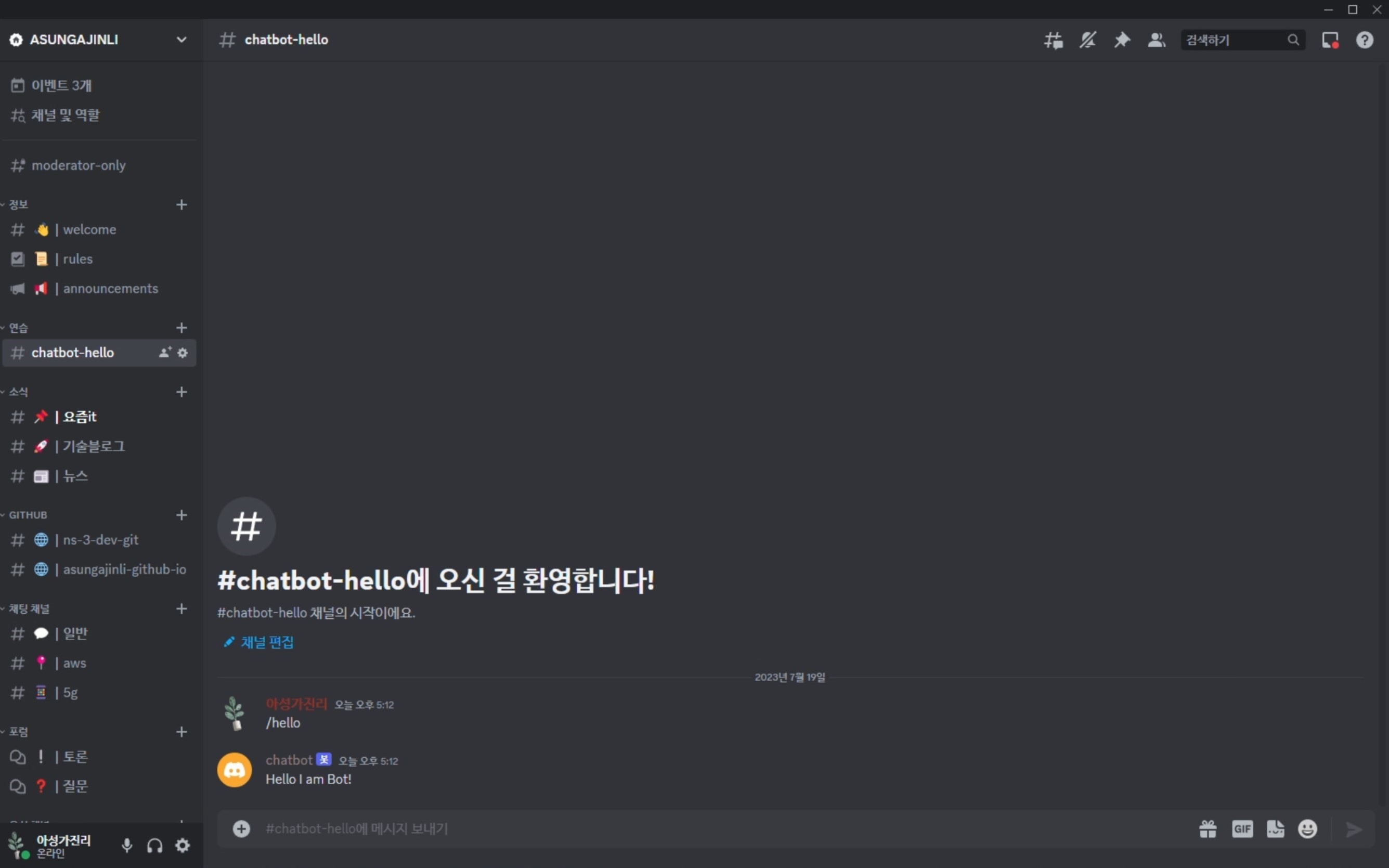
async def hello(ctx):
await ctx.send('Hello I am Bot!')
app.run(config.bot_token)
bot_token = '앞서 생성한 bot_token'
pip install boto3
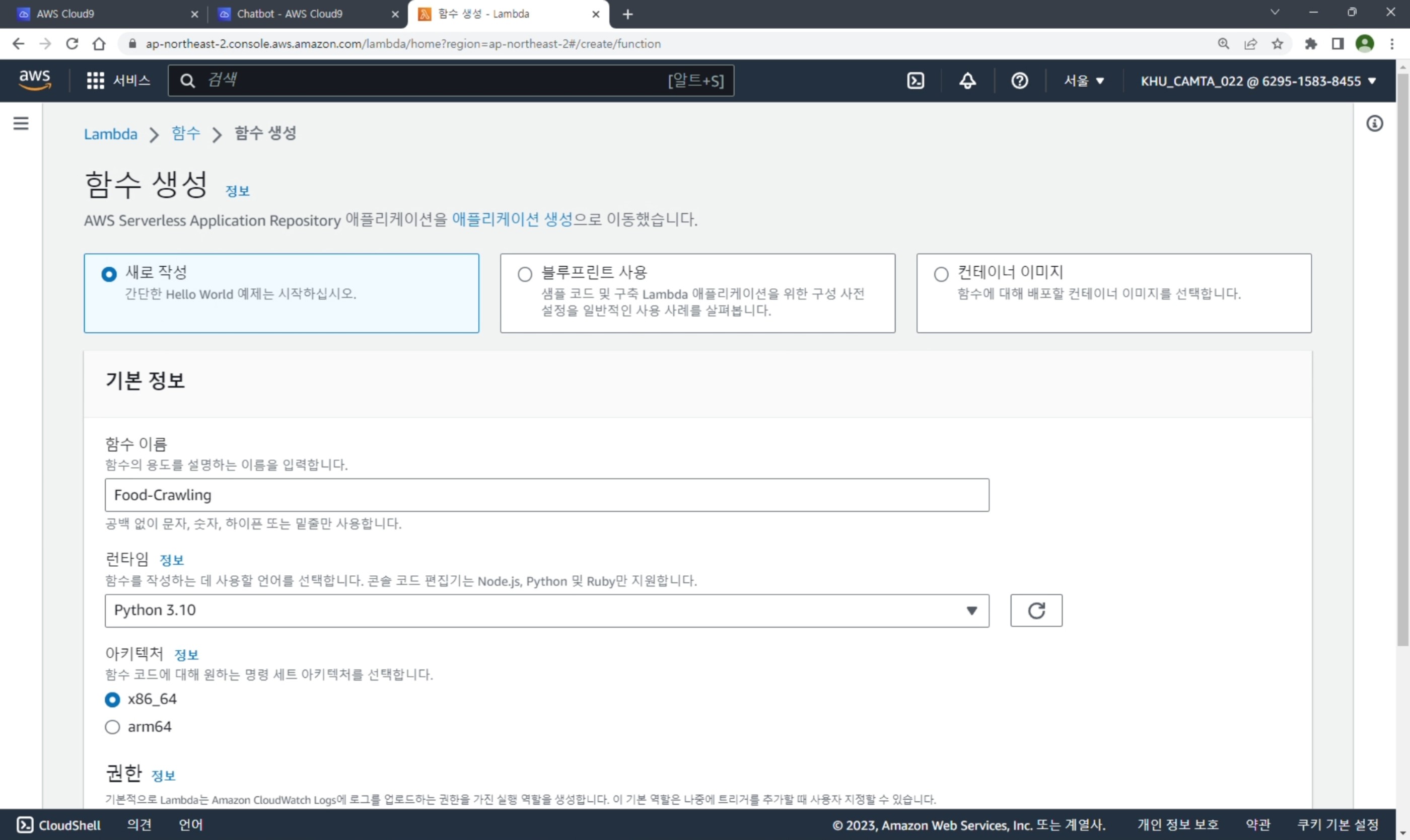
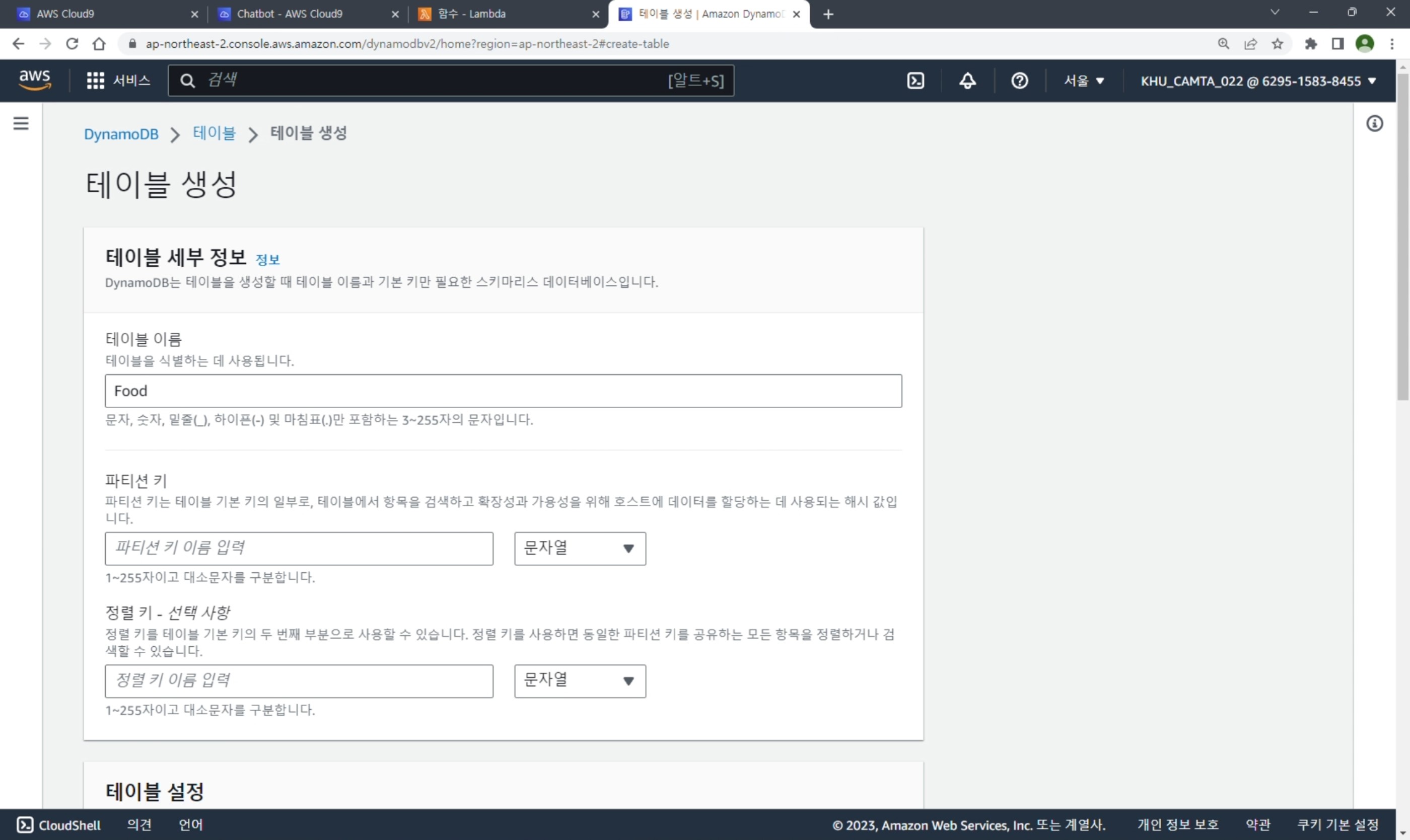
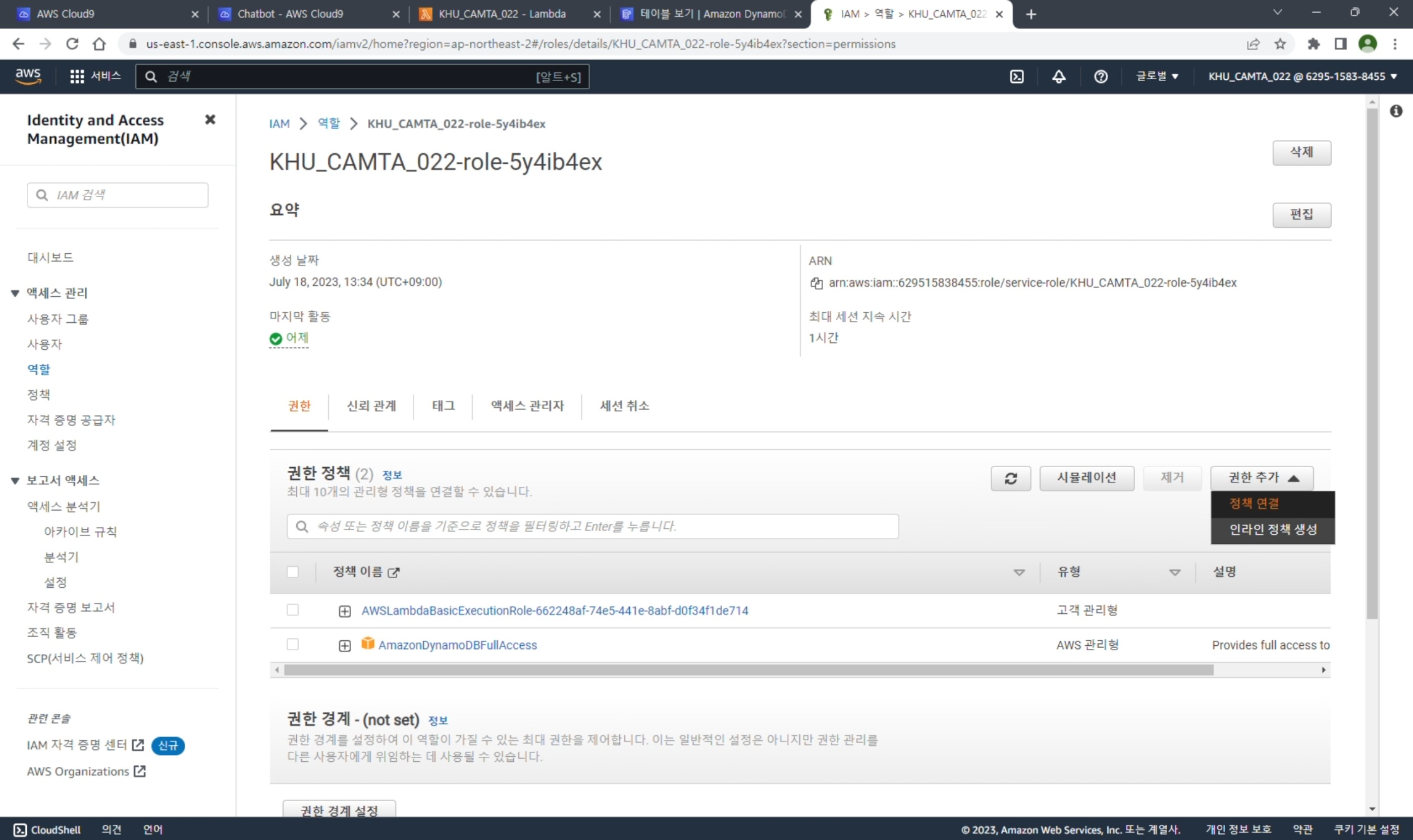
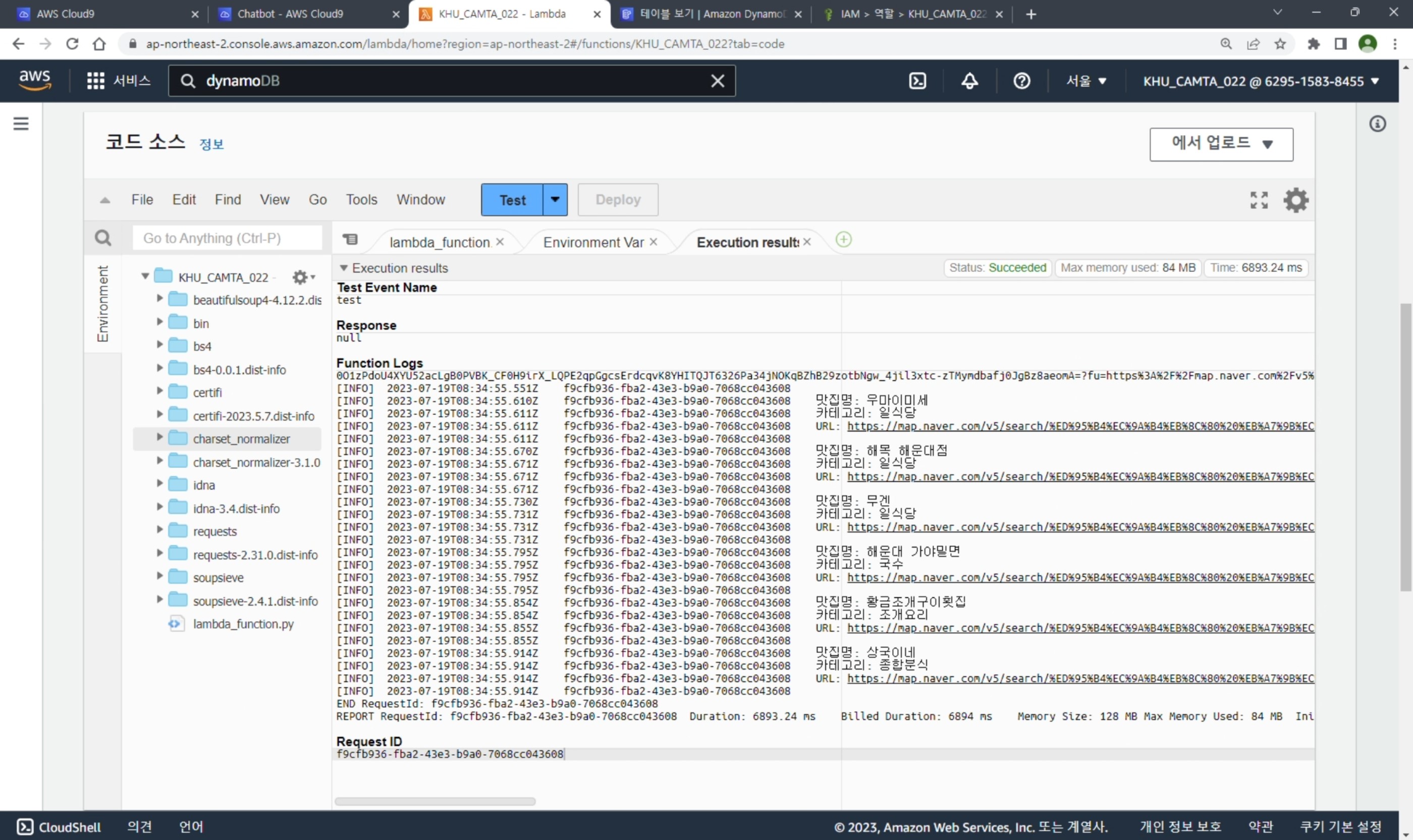
Cloud9 Github Push
echo "# discord-chatbot" >> README.md
git init
git add README.md
git commit -m "first commit"
git branch -M main
git remote add origin https://github.com/asungajinli/discord-chatbot.git
git push -u origin main
git config --global user.name "Your Name"
git config --global user.email you@example.com
import requests
from bs4 import BeautifulSoup
import boto3
import logging
import cssutils
def lambda_handler(event, context):
dynamodb = boto3.resource('dynamodb')
table_name = 'KHU_CAMTA_022' # 테이블 이름
url = "https://search.naver.com/search.naver?sm=tab_hty.top&where=nexearch&query=%ED%95%B4%EC%9A%B4%EB%8C%80+%EB%A7%9B%EC%A7%91&oquery=%ED%98%84%EC%9E%AC+%EC%9C%84%EC%B9%98+%EC%A3%BC%EB%B3%80+%EB%A7%9B%EC%A7%91&tqi=i7hAYdp0JXossQtaN6Rsssssswd-435668"
response = requests.get(url)
html_content = response.text
soup = BeautifulSoup(html_content, "html.parser")
results = soup.select("div.CHC5F")
logger = logging.getLogger()
logger.setLevel(logging.INFO)
for i, result in enumerate(results):
title = result.select_one("span.place_bluelink.TYaxT").text.strip()
url = result.select_one("a.tzwk0")['href']
category = result.select_one("span.KCMnt").text.strip()
img_style = result.select_one("div.K0PDV")['style']
style = cssutils.parseStyle(img_style)
img_url = style['background-image']
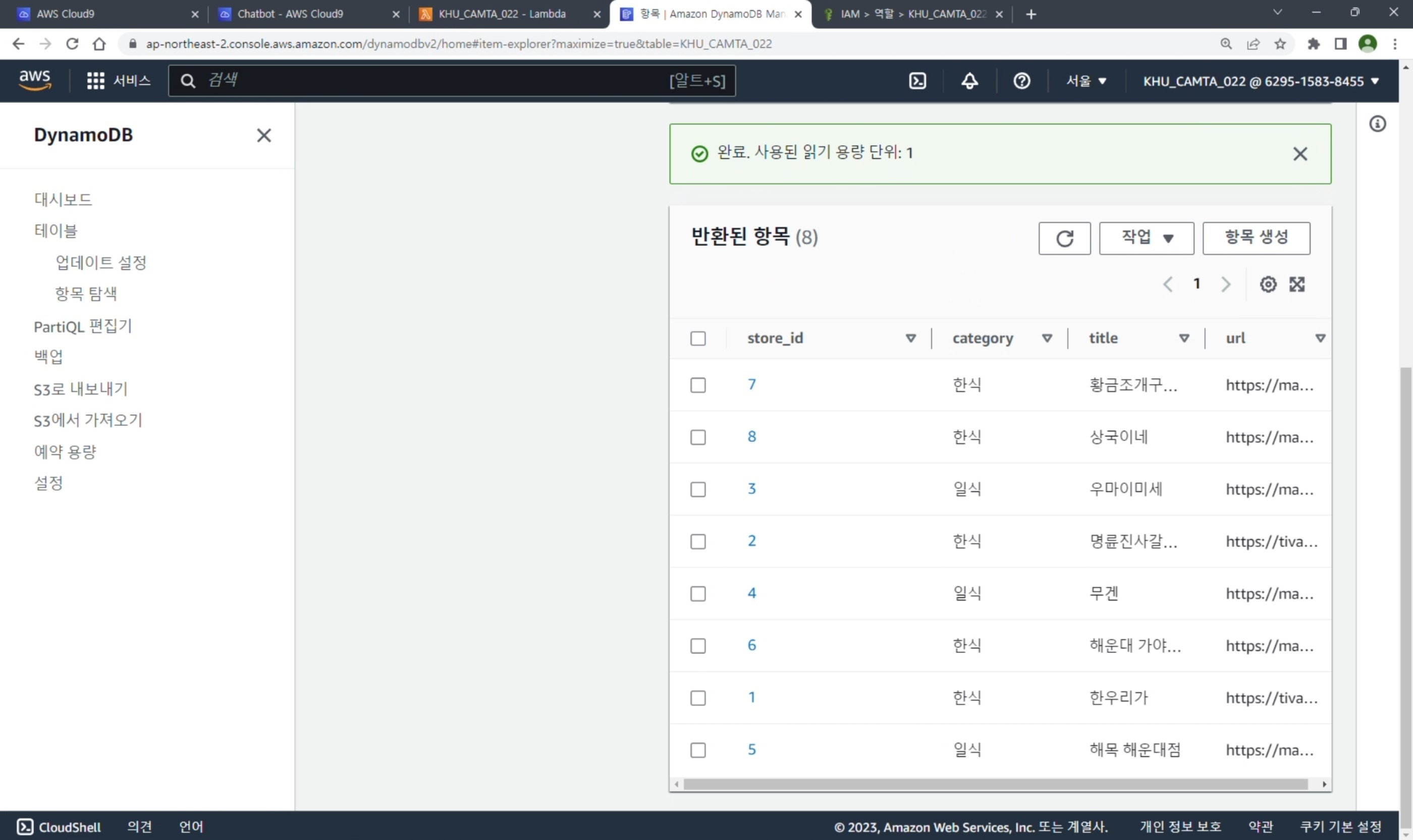
# DynamoDB에 데이터 삽입
table = dynamodb.Table(table_name)
table.put_item(
Item={
'store_id': i + 1,
'title': title,
'url': url,
'category': category,
'img_url': img_url
}
)
logger.info(f"맛집명: {title}")
logger.info(f"카테고리: {category}")
logger.info(f"URL: {url}")
logger.info("") # 빈 줄을 출력하여 구분