Elastic 소개
과거에는 기업들이 생성한 정형 데이터가 주를 이루었다면, 이제는 개인들이 생성하는 정형/비정형 데이터들을 다루게 되었다. 데이터 규모와 다양성이 커지면서, 검색은 더욱 중요해졌다. 이제는 검색이 그저 사전이나 포털 사이트 같은 일부 서비스에서만 국한되지 않는다. SNS, 쇼핑몰, 게임 부터 마케팅, 개발 까지 검색 기능의 활용 분야는 매우 광범위하다.
이러한 상황에 Elasticsearch는 기존 RDBMS의 한계를 극복하는 검색엔진으로 주목받고있다. RDB는 데이터들의 관계와 매칭을 통해 검색을 수행하는 순방향 인덱스(forward index) 방식이다. 쉽게 말해 9×9 큐브에서 (1,1)부터 (9,9)까지 길을 찾아간다. 그에 반해 Elasticsearch는 집게로 데이터를 뽑아내는 역방향 인덱스(inverted index) 방식으로 검색 속도가 더 빠르다. 또한 N-gram 기반 full-text 검색으로 유의어, 동의어, 형태소 분석이 가능하다. RDB는 SQL 방식, Elasticsearch는 NoSQL 방식이다. SQL에 대한 내용은 따로 다루기로 하고, 여기서는 Elasticsearch가 NoSQL의 특징을 따라간다는 것을 알면 되겠다. 아래는 RDB와 Elasticsearch를 비교해 정리한 표이다.
| RDB(SQL) | Elasticsearch(NoSQL) | |
|---|---|---|
| 데이터 저장 방식 | 정규화 | 역정규화 |
| Full-text 검색 속도 | 느림 | 빠름 |
| 의미 검색 | 불가능 | 가능 |
| Join | 가능 | 불가능 |
| 수정/삭제 | 빠름 | 느림 |
| 데이터 저장 모델 | Table | Json document / key-value 등 |
| 개발 목적 | 데이터 중복 감소 | 확장가능성 / 수정가능성 |
| Schema | 엄격한 데이터 구조 | 유연한 데이터 구조 |
| 장점 |
명확한 데이터 구조 보장 데이터 중복 없이 한번만 저장 |
유연하고 자유로운 데이터 구조 새로운 필드 추가 자유로움 수평적 확장 용이 |
| 단점 |
시스템의 크기에 따른 복잡한 query 수평적 확장이 힘들어서 비용이 큰 수직적 확장 사용 |
명확한 데이터 구조 보장 X 데이터 중복 발생 가능 |
| 주요 사용 환경 |
데이터 구조가 명확한 경우 데이터 update가 잦은 시스템 |
데이터 구조가 명확하지 않은 경우 udatae가 자주 일어나지 않는 경우 |
RDBMS가 좋아, 또는 Elasticsearch가 최고야 같은 이분법적인 비교는 좋지 않다. 각자의 장단점은 존재하며, 둘을 병행해서 사용하기도 한다.
Elastic Stack & Elasticsearch 구조
Elastic Stack이란 Elastic 사의 오픈소스 데이터 분석 플랫폼으로서 Elasticsearch를 포함하고 있다. 데이터 분석에 필요한 모든 유형의 데이터를 검색, 분석, 시각화한다. 예전에는 Elasticsearch, Kibana, Logstash의 앞글자를 따 ELK Stack이라 부르기도 하였지만, Beats와 같은 다양한 기술들이 추가되며 Elastic Stack이라 한다.
Elasticsearch란?
확장 | 스케이 업이 아닌, 수평적 스케일링 → 속도, 확장성, 유연성이 좋아짐.
코어들의 스펙을 맞춰야함.
기능 | 검색
NoSQL vs RDBMS
의미 검색 → 형태소 분석이 가능하기 때문에.
Join | 불가능
검색 기능 상세
Elasticsearch 활용 사례
Use case
KB차차차, WIPS ON, 공공데이터포털
라이선스 및 기술 지원 정책
Basic - Gold - Platinum - Enterprise
HW 권장 사양
Elastic Cloud 소개
소개
클라우드 → IaaS, PaaS, SaaS
HA - 고가용성
- 클러스터 대부분 3서버
- 10노드가 넘어가면 부하 발생할 수 있다.
Cluster name이 같으면 그 내의 node name은 중복되면 안된다.
node
node-1 ~ … 앞에 별표가 있는 게 master
linux로 설치
사용자 계정으로 설치해야 함.
elasticsearch-8.xx.tar
$ cd config
$ ll
$ vi jvm.options
데이터 기본 구조
GET index_name/
{
"index_name": {
"aliases": {
...
},
"mappings": {
...
},
"settings": {
...
}
}
}
Index 기본 구조 aliases: index 별칭 관리
조회
GET _alias/alias_name(생략 가능)
추가 및 제거
POST _aliases
{
"actions": {
"add" OR "remove": {
"index": "index_name",
"alias": "alias_name"
}
}
}
mapping: index 필드 타임 관리
조회
GET index_name/_mapping
수정
PUT index_name/_mapping
{
"properties": {
"field_name": {
"type": "field_type"
}
}
}
setting: index 구성 설정 관리
조회
GET index_name/_settings
수정
PUT index_name/_settings
{
...
}
한번에 관리하는 게 Index Template
데이터 전처리
데이터 타입 확인
GET index_name/
Kibana 페이지의 ‘Analytics / Machine Learning / Data Visualizer’에서 data file을 import 할 수 있다.
딱히 활용할만한 데이터가 없다면 공공데이터포털의 데이터를 활용해보자.
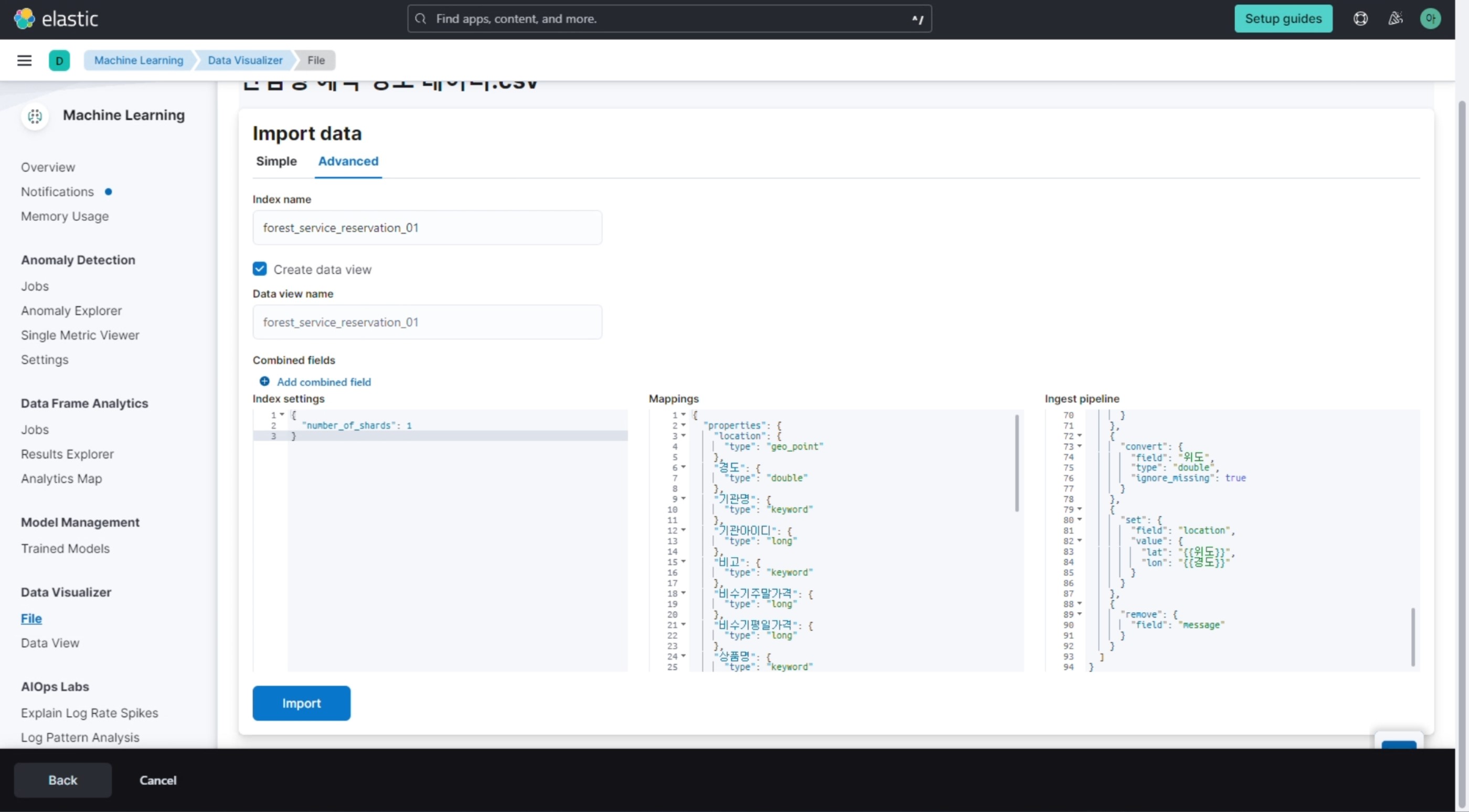
데이터를 import하기 전 전처리 과정을 거칠 수 있다.
‘geo_point’타입의 “location”을 새롭게 맵핑하고, 위도와 경도를 통해 location을 할당하도록 pipeline을 정의해 주었다.
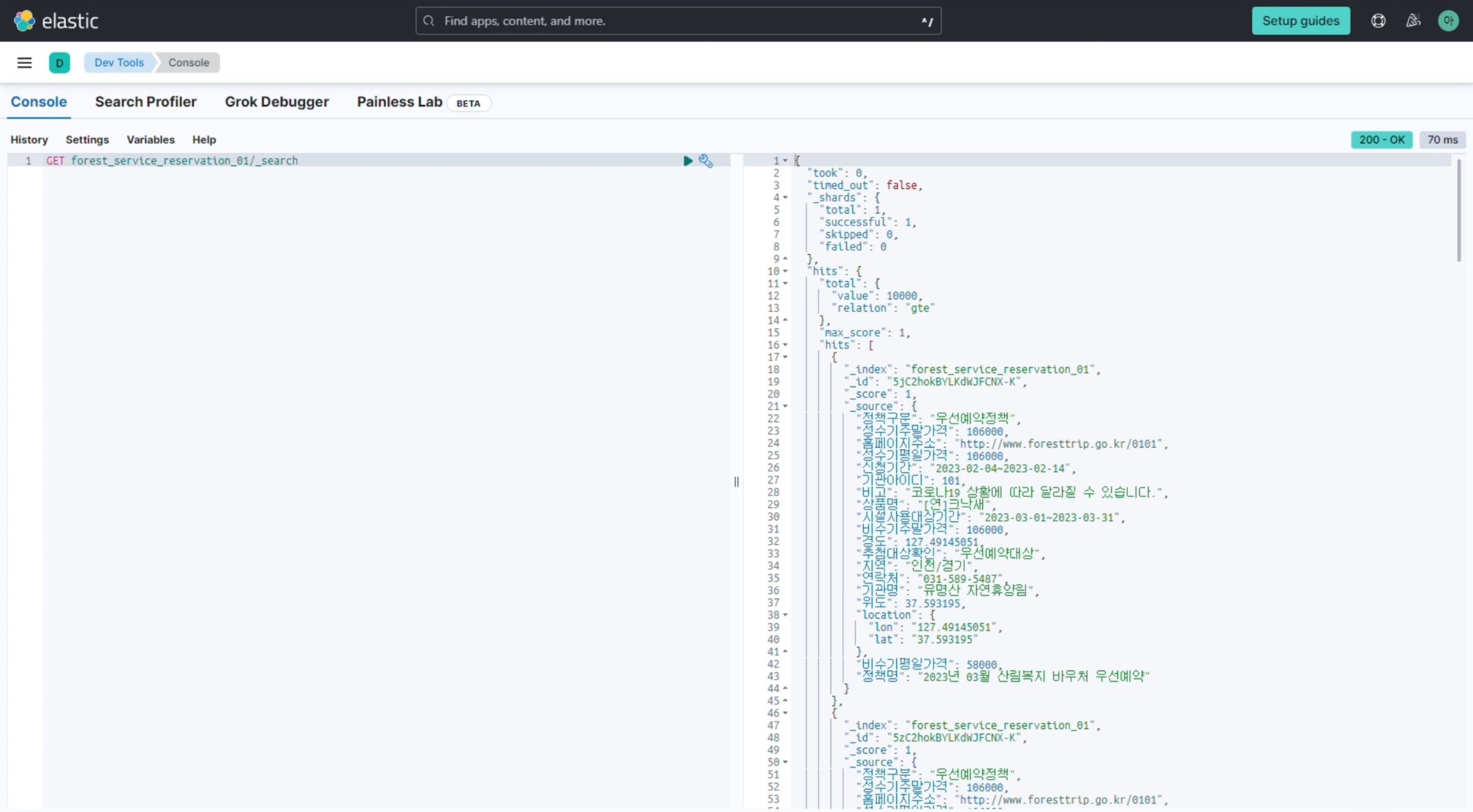
GET forest_service_reservation_01(index명)/_search로 데이터를 확인해보면, location이 위도와 경도 값으로 정의된 것을 확인할 수 있다.
데이터 시각화
- 관리자 화면
- 시스템 성능 모니터링
-
데이터 시각화
통신사 데이터 모바일 이용 통계 대시보드 중고차 매매 현황 대시보드 장비별 로그 모니터링 대시보드 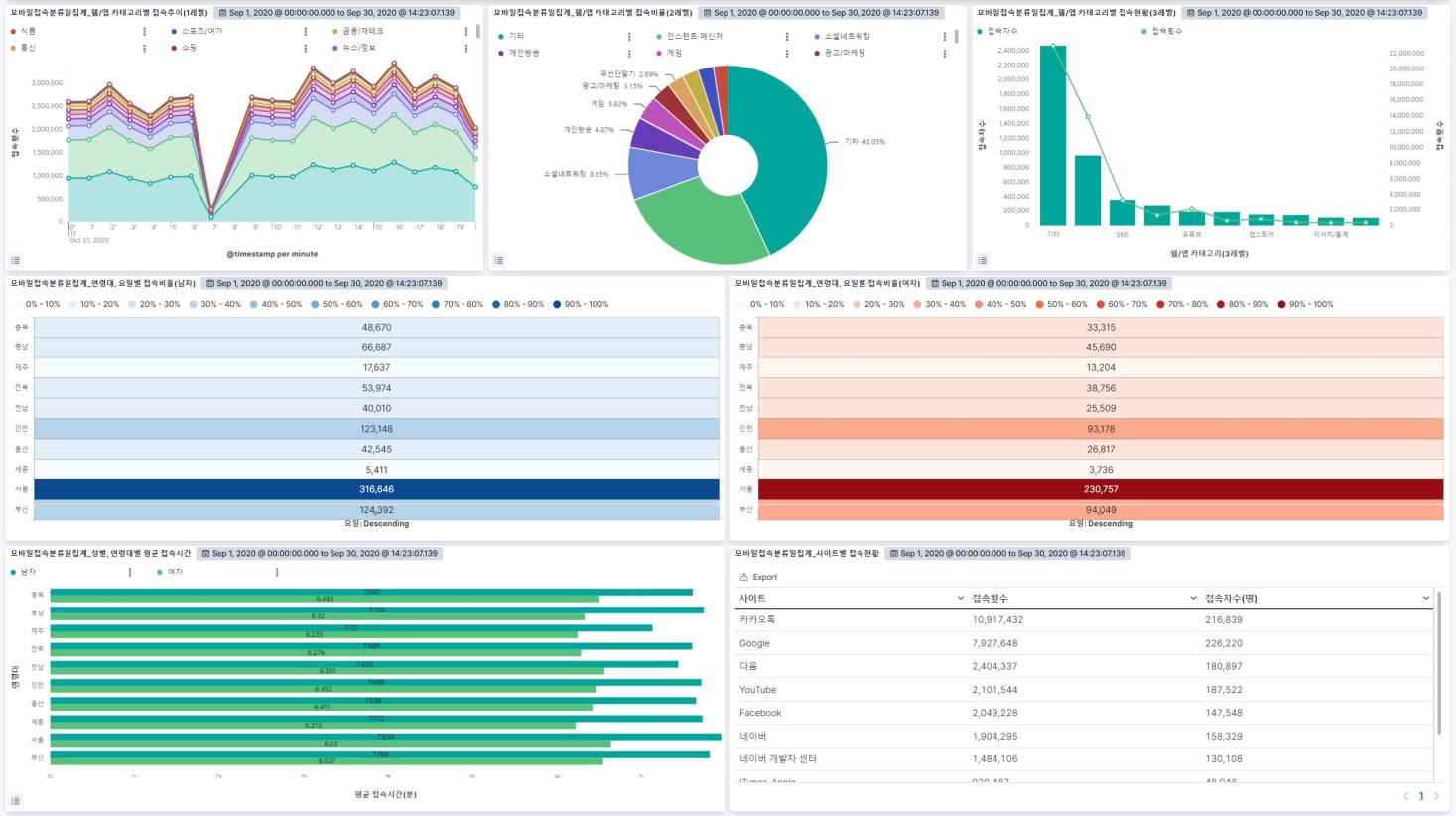
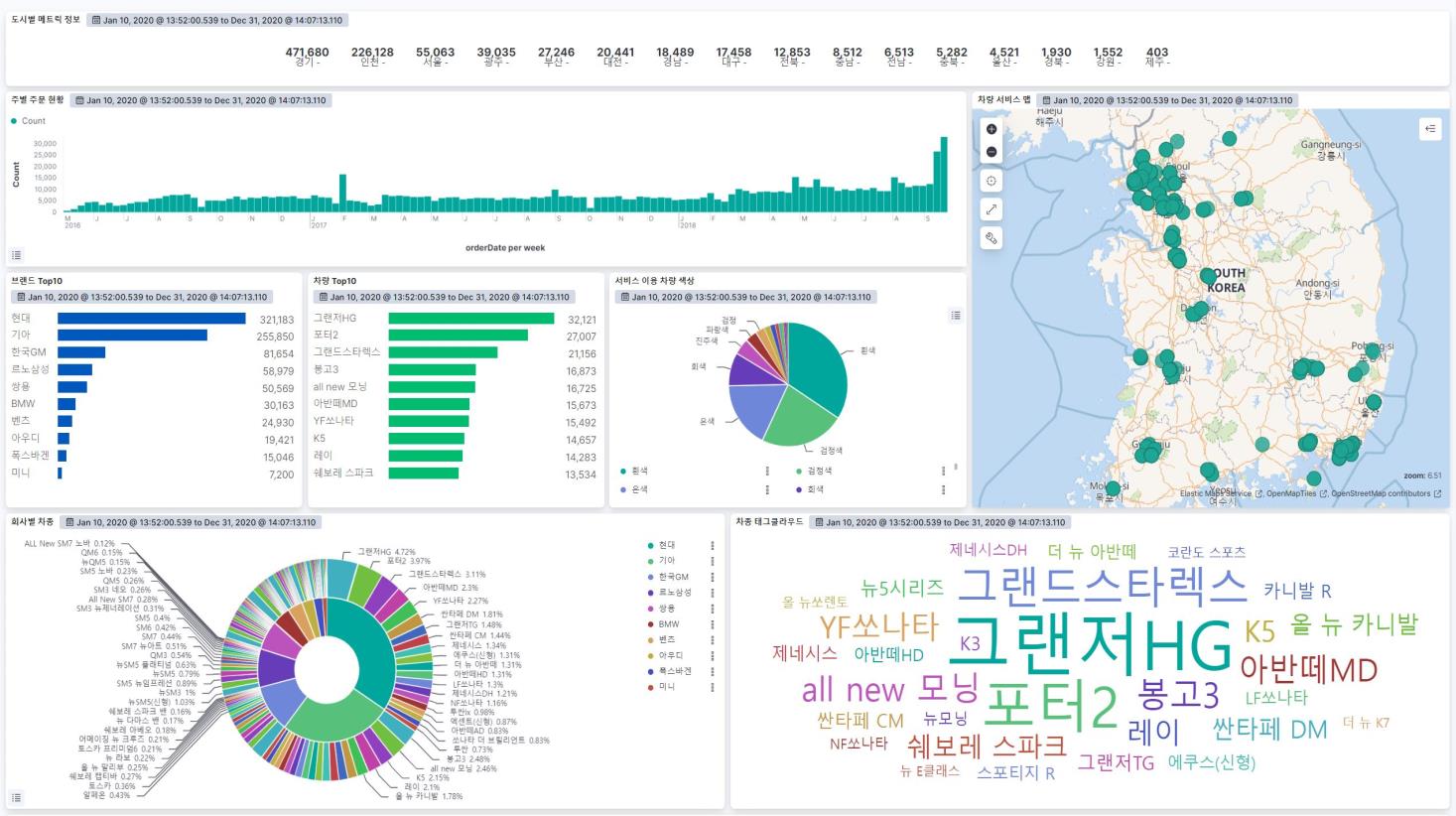
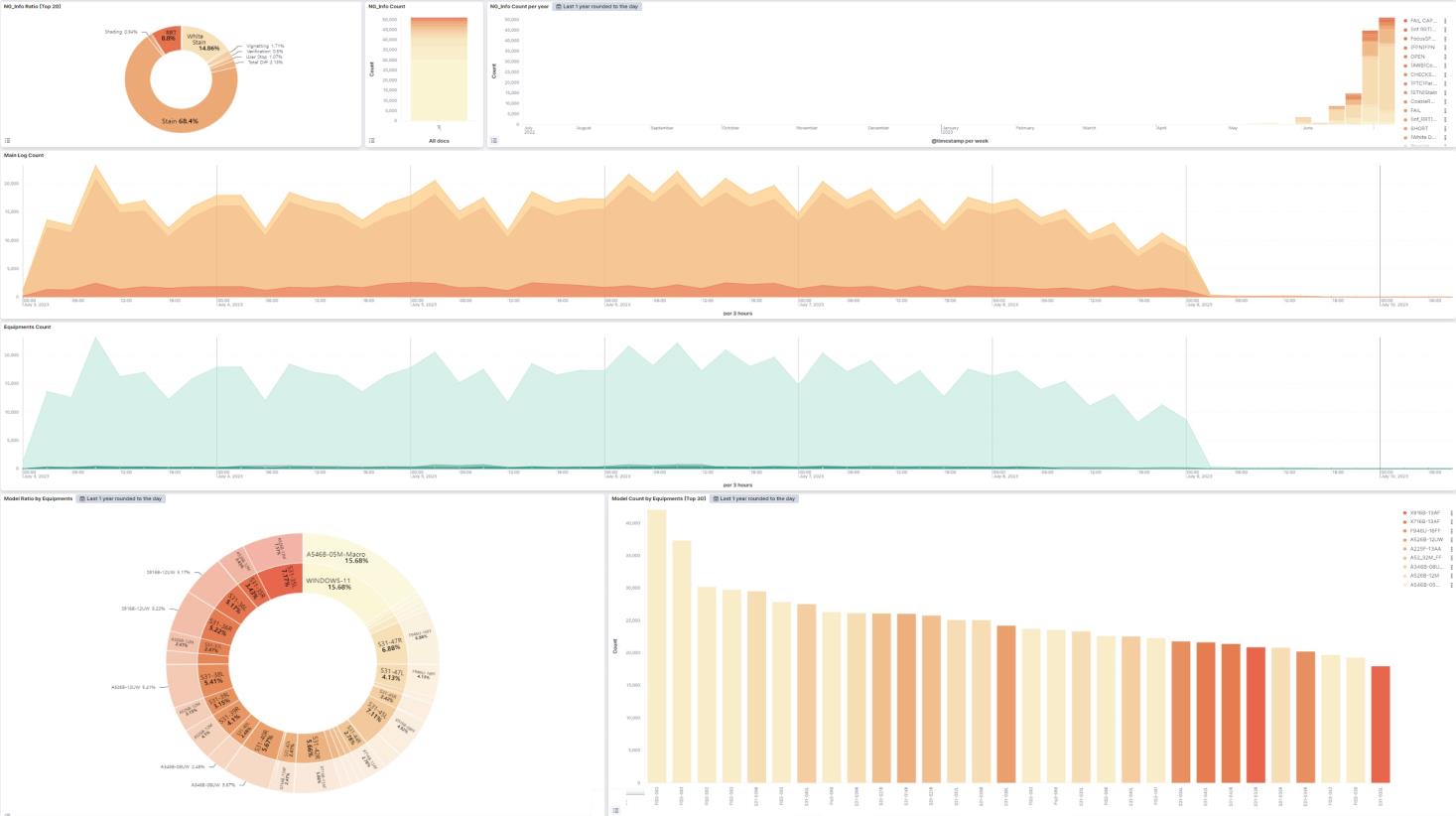
이제 본격적으로 시각화를 진행해보자.
‘Analytics / Visualize Library’에서 visualization을 생성할 수 있다. 버튼을 누르고 아래와 같이 맵을 생성하고 대시보드에 저장해보자.
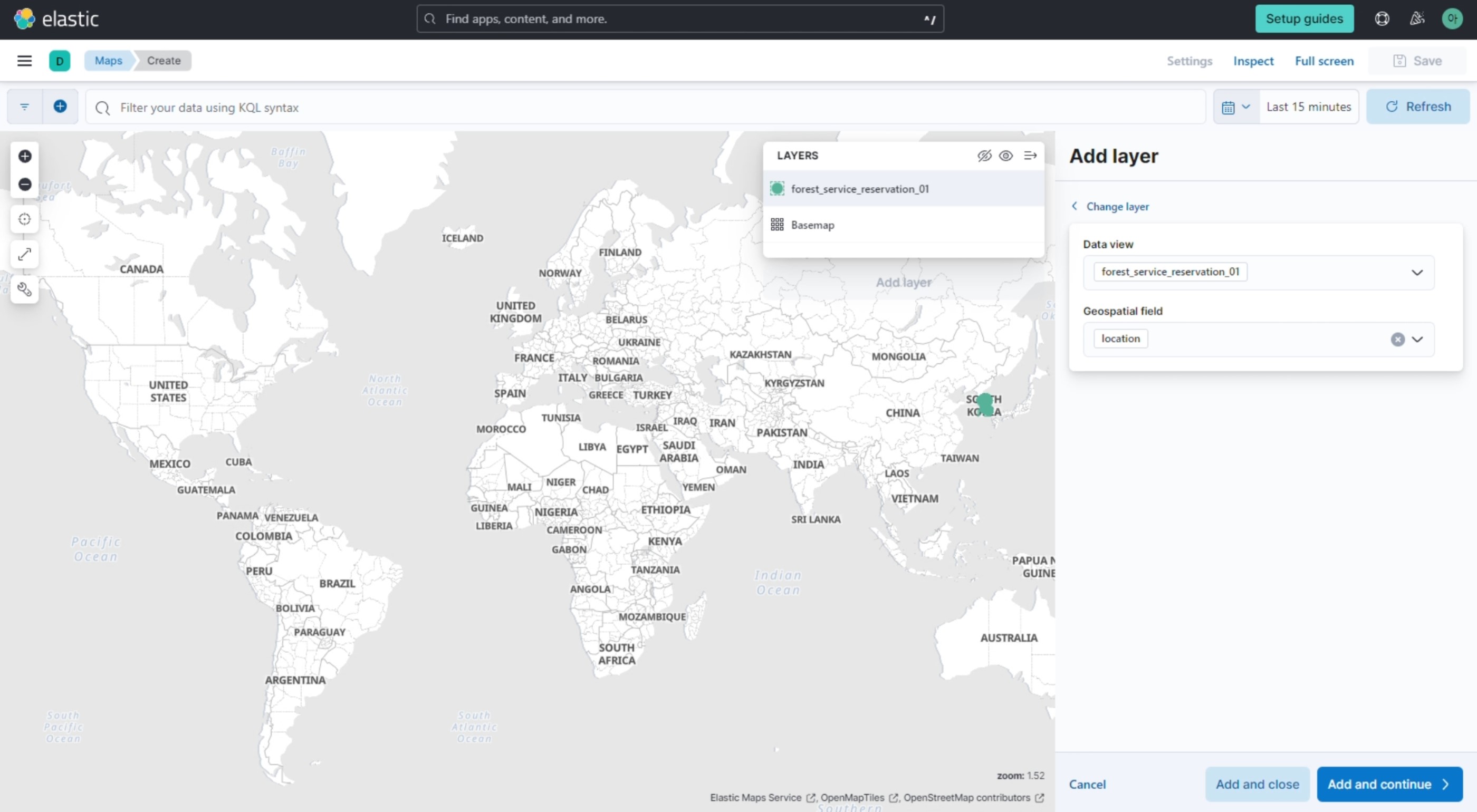
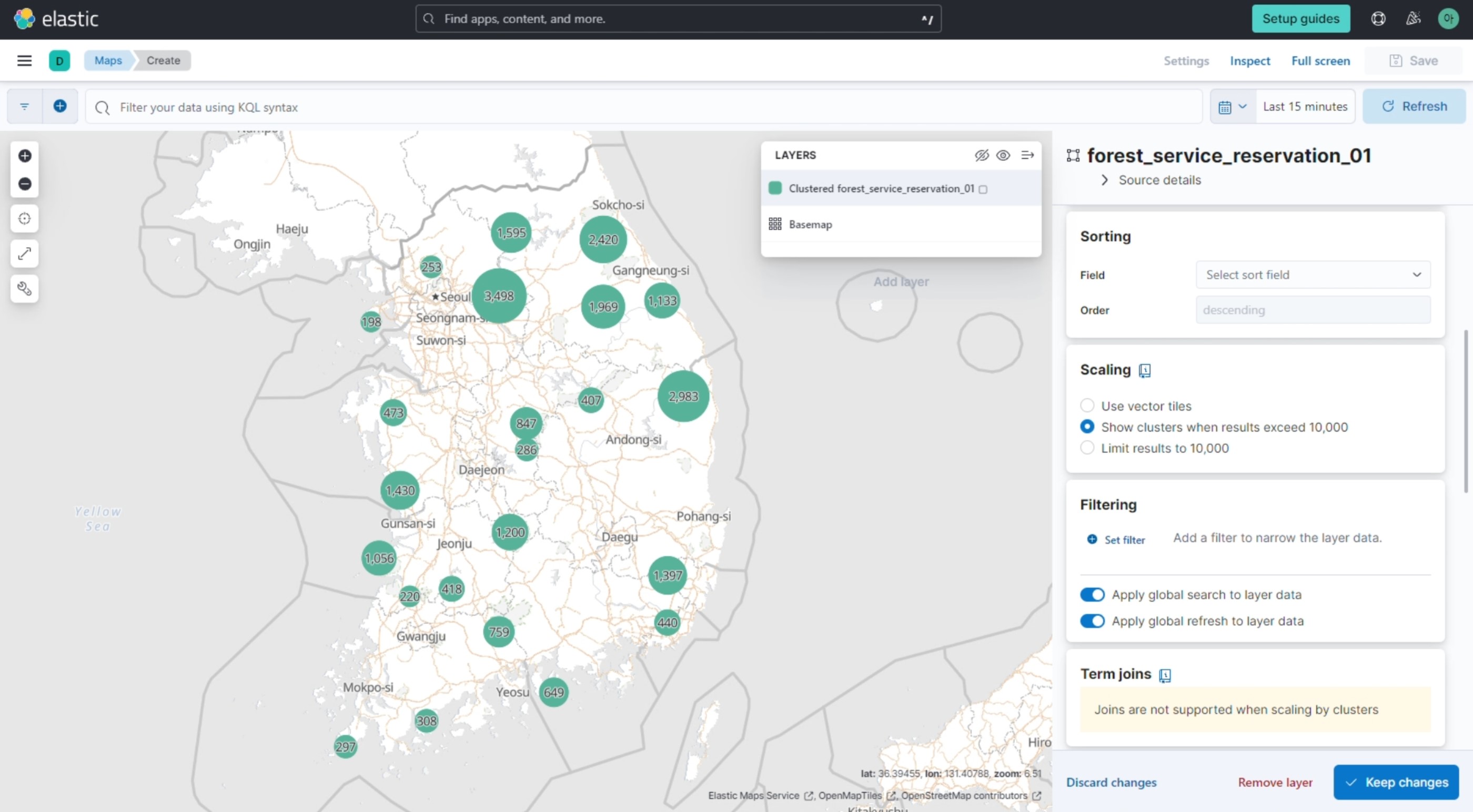
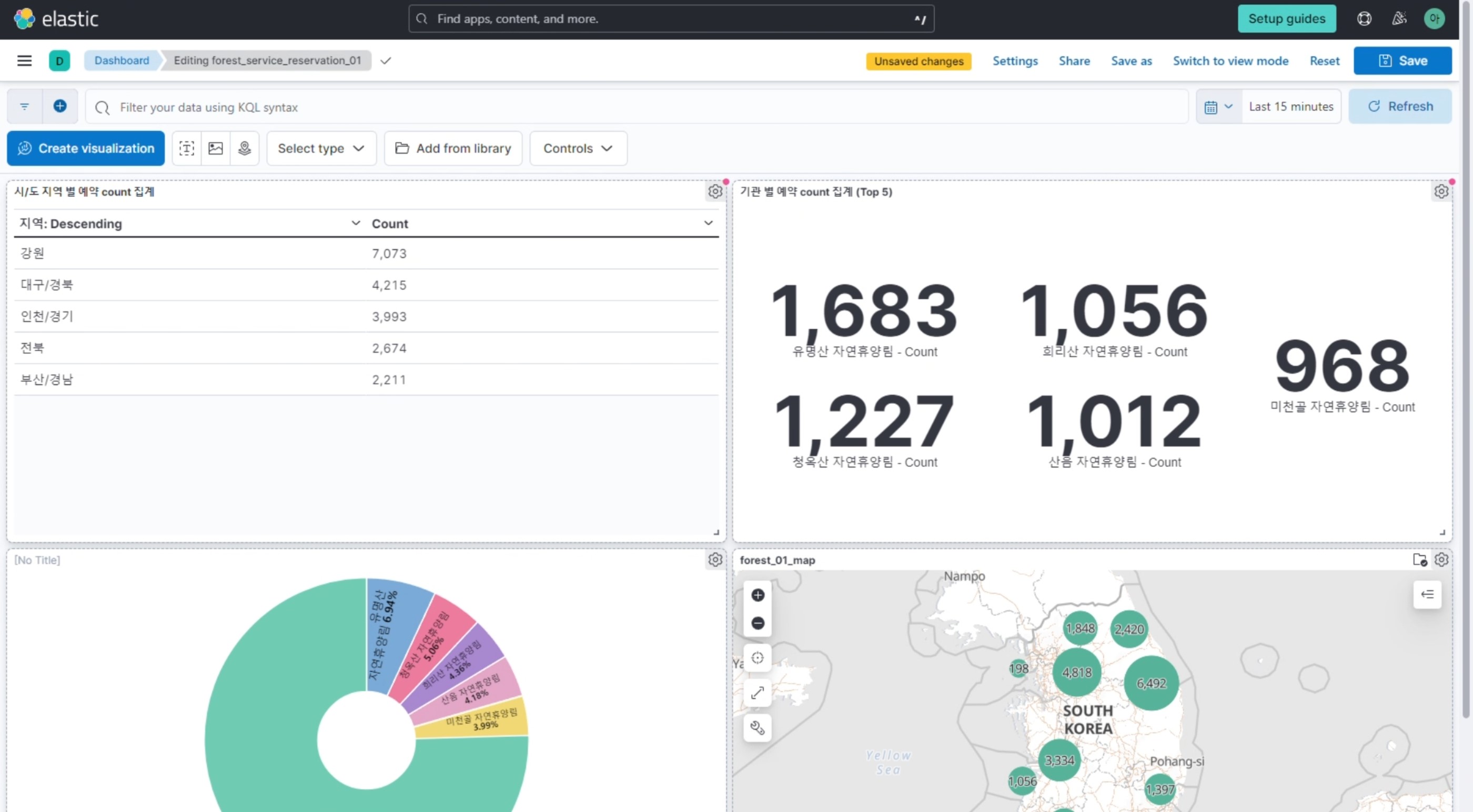
표와 그래프 등의 다양한 시각화 데이터를 생성하고, 대시보드에서 확인, 관리할 수 있다.
Reference
- 이 포스트는 2023년 7월 7일 ~ 8월 25일 기간동안 시행된 ‘AWS X 경희 캠타 여름특강’을 바탕으로 작성되었습니다.
- “처음부터 시작하는 Elastic” Youtube, 한국 Elastic 사용자 그룹, Nov. 2021, https://youtube.com/playlist?list=PLhFRZgJc2afp0gaUnQf68kJHPXLG16YCf.
- Aravindputrevu, “Dec 15th, 2020: [EN] Preparing for an Elasticsearch Interview”, ATLASSIAN, [Online]. Available: https://discuss.elastic.co/t/dec-15th-2020-en-preparing-for-an-elasticsearch-interview/258087. [Accessed: 07- July- 2023].