Cassandra 데이터 정렬 문제 - 3
2편에서 다루었었던 내용을 보면 정수형 데이터 __Id를 Clustering Key로 설정했었다.
Jira에 커미터분께서 _time과 같은 시간 데이터를 Clustering Key로 설정하는 것이 어떤가 하는 의견을 주셨다.
_time 받아오기
Dataextraction의 기존 SQLTransform.py에서는 사용자가 선언한 Features만 받아오게 되어있다.
여기에 _time을 받아오는 코드를 추가해주었다.
q_features = "`_time`,"
아래와 같이 _time 데이터를 성공적으로 받아온 것을 확인할 수 있다.
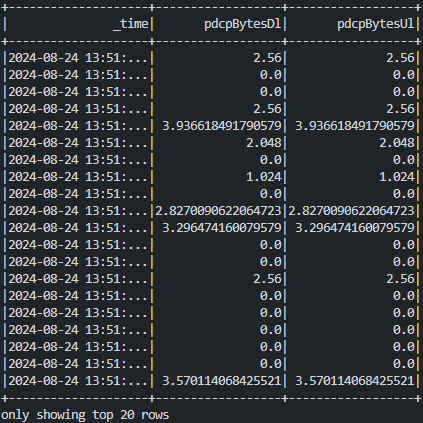
_time을 Clustering Key로 설정
다시 CassandraSink.py로 돌아가서 _time을 Clustering Key로 설정해주었다.
기존 buildCreateTable()함수의 query에서 Key 설정 부분을 아래와 같이 변경해주고,
query = "CREATE TABLE " + self.tableName + ' ( "partition_key" text,'
...
query = query + 'PRIMARY KEY (("partition_key"), "_time"));'
write() 함수도 변경해주었다.
sparkdf = sparkdf.select("*").withColumn("partition_key", lit('1'))
결과
아래와 같이 _time이 Clustering Key로 설정된 것을 확인할 수 있다.
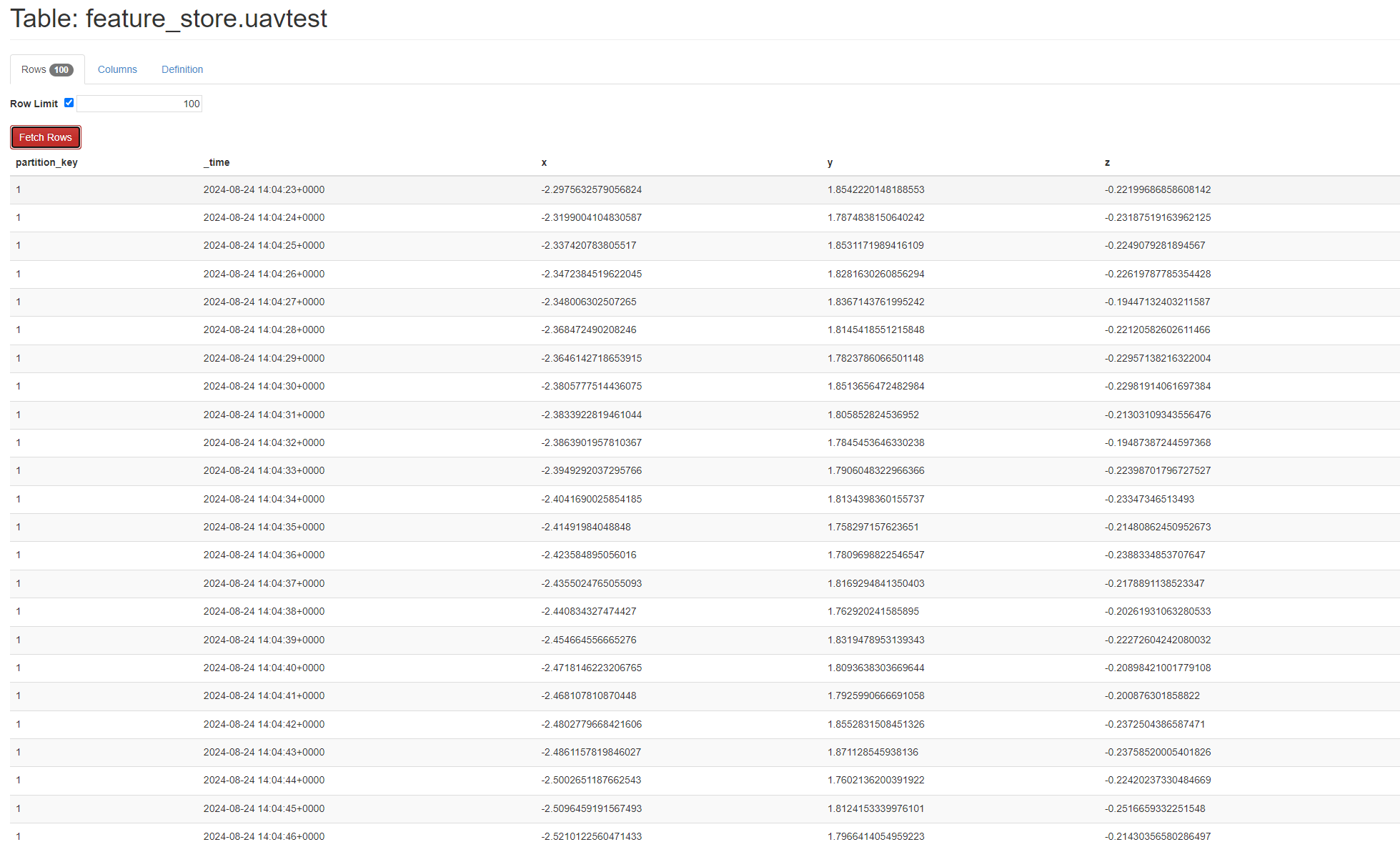
Cassandra 데이터 정렬 문제 - 2
Federated Learning framework 개발