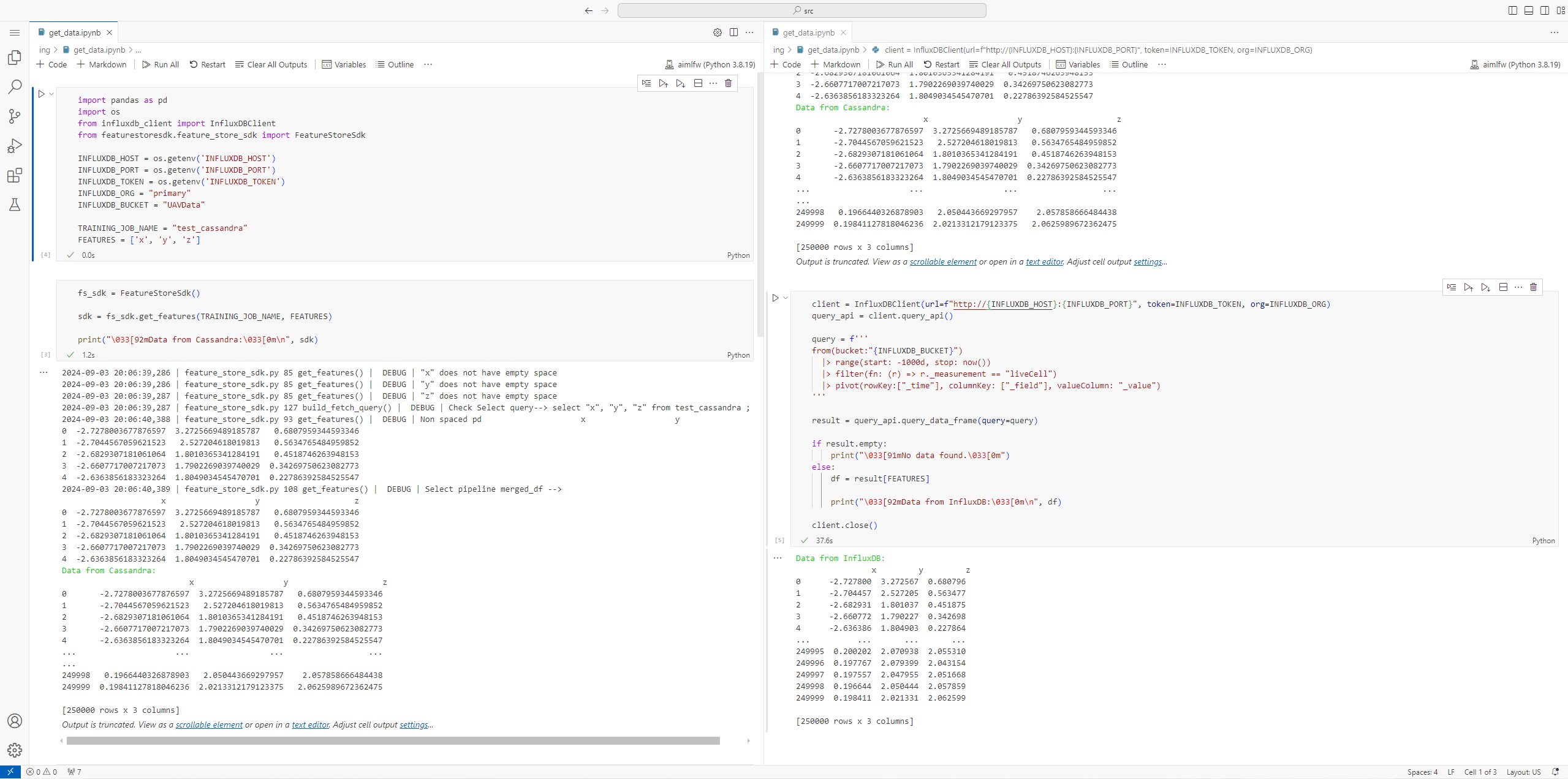
Jira 이슈
이전에 설명한 Cassandra 데이터를 가져올 때의 문제에 대한 이슈를 Jira에 등록했고, 답변을 받았다.
커미터 분들이 처음에는 데이터 정렬이 꼭 필요한지에 대한 의문을 제기하셨다. 이에 대해 데이터 정렬이 필요한 이유에 대해 설명했고, 시계열 데이터의 LSTM 모델 사용에 있어서 데이터 정렬이 필요하다는 것에 동의하셨다.
정렬 방식의 경우 __Id를 기준으로 정렬하는 것이 비효율적이기 때문에 Cassandra의 query 등을 통해 정렬할 수 있는지 답변을 받았다.
Cassandra 데이터
feature_store_sdk 쿼리 수정
처음에는 단순히 feature_store_sdk.py에서 정의된 query를 수정하고자 하였다.
def build_fetch_query(self, trainingjob_name, features):
"""
Builds simple sql query for given table and features list
"""
col = ""
for feature in features:
col = col + feature + ", "
col = col[:-2]
query = "select " + col + " from " + trainingjob_name + " ;"
self.logger.debug("Check Select query--> " + query)
return query
def build_fetch_query_single(self, trainingjob_name, feature):
"""
Builds simple sql query for given table and single feature
"""
return "select " + feature + " from " + trainingjob_name + " ;"
위와 같이 query가 정의되어있는데(원본) 우선 ORDER BY를 통해 정렬을 수행하고자 하였지만,
문제는 __Id가 Partition Key로 설정되어 있고, Cassandra에서 Partition Key로는 ORDER BY를 수행할 수 없다는 것이다.
그래서 다른 해결 방법을 찾아봐야했다.
data-extraction 수정
CassandraSink.py의 buildCreateTable() 함수에 정의된 query를 보기 쉽게 바꾸면
CREATE TABLE tableName (
"__Id" BIGINT,
"column1" text,
"column2" text,
"column3" text,
...
PRIMARY KEY("__Id")
);
로 정의되어 있다. 알다시피 __Id가 Partition Key로 설정되게 되어 있다.
그래서 __Id를 Clustering Key로 설정하고, 따로 Partition Key를 설정하였다. Cassandra에서는 Partition Key로 ORDER BY를 수행할 수도 있고, 데이터를 올릴 때 자동적으로 Clustering Key로 정렬을 수행하게 되어 있다.
CREATE TABLE tableName (
"partition_key" text,
"__Id" BIGINT,
"column1" text,
"column2" text,
"column3" text,
...
PRIMARY KEY("partition_key", "__Id")
);
buildCreateTable() 함수의 query 마지막 부분을 아래와 같이 수정하고,
query = query + 'PRIMARY KEY (("partition_key"), "__Id"));'
추가적으로 write()함수에 partition_key column을 추가하였다.
...
sparkdf = sparkdf.select("*").withColumn("partition_key", lit('1')) \
.withColumn("__Id", monotonically_increasing_id())
...
결과
수정된 결과를 확인하기 위해 수정 사항을 반영한 data-extraction을 새롭게 빌드했다.
sudo buildctl --addr=nerdctl-container://buildkitd build \
--frontend dockerfile.v0 \
--opt filename=Dockerfile \
--local dockerfile=data-extraction \
--local context=data-extraction \
--output type=oci,name=data-extraction:sungjin | sudo nerdctl load --namespace k8s.io
aimlfw-dep/RECIPE_EXAMPLE/example_recipe_latest_stable.yaml의 data-extraction image를 수정된 data-extraction image로 변경해주었다.
...
dataextraction:
image:
repository: data-extraction
pullPolicy: IfNotPresent
tag: "sungjin"
...
Pod를 재배포 해주고,
bin/uninstall.sh
bin/install.sh -f RECIPE_EXAMPLE/example_recipe_latest_stable.yaml
Trainingjob을 생성해주니, Data extraction이 잘 작동하는 것을 확인할 수 있었다.
Cassandra에도 Partition Key와 Clustering Key가 반영되어 데이터가 잘 올라가는 것을 확인할 수 있다.
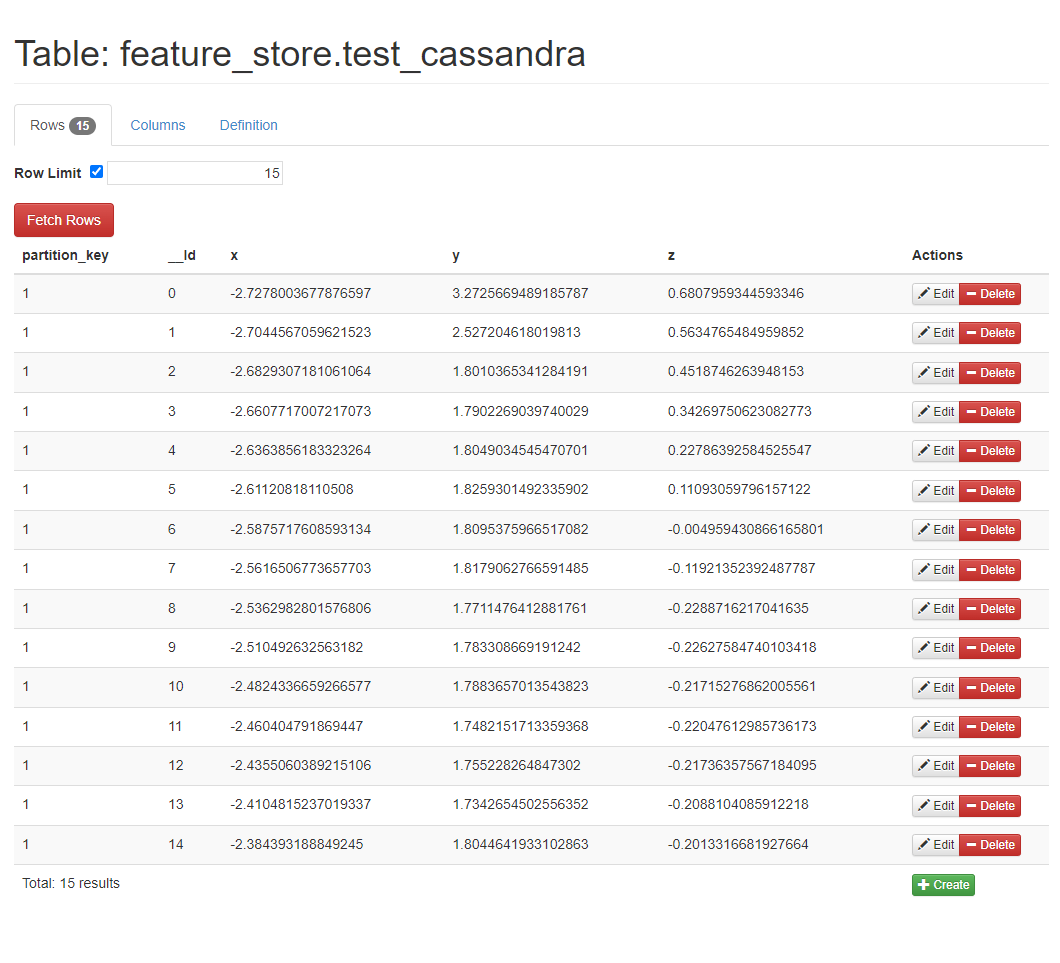
feature_store_sdk.py의 수정 없이 InfluxDB 데이터와 동일한 데이터를 Cassandra에서 받아올 수 있다.